
NLP Project -- Pronounciation Prediction for Teochew Dialect (Part 1)

Lately, inspired by my boyfriend’s post, I decided to take a deeper look at my mother tongue – Teochew dialect. It is a dialect of the Southern Min, China; However, it has a very different tonal system from Mandarin that Teochew people would call it a language. Below is the highlight taken from a video snippet about Teochew tones.
As a native speaker, it is easy to speak the language but hard to spot the grammer rules. Therefore, this NLP project is created to explore the pronunciation patterns for the Teochew dialect. The end goal is for a machine to guess the pronounciation for words in Teochew given its Mandarin counterpart.
The part 1 of this series will focus on tones. I will talk about what dataset I used to conduct the experiments, what are some important data wrangling steps, and what visualization techniques (contingency tables, corresponding analysis) to help interpret the results.
A Good Dataset is Half the Battle
Although NLP tasks generally involve fewer data points than Computer Vision, at least a few hundred data points are required to draw any statistically significant conclusion. I first came across the CLICS dataset, where different Chinese dialects/languages are transcribed, including Teochew, denoted as Chaozhou, and Beijing (Standard Mandarin). There are roughly 800 words in each dialect’s dataset. These datasets are intended for semantic analysis across many languages.
For those of you who are unfamiliar with Teochew, it does not have any standardized writing system. Instead, people use Chinese characters with similar sounds, which vary from person to person. However, the CLICS dataset does not preserve Chinese characters for Teochew. Different varieties are joined on the concept level. If we directly translate the English into Mandarin, the one-to-one correspondance between character and pronounciation in Teochew would be lost. The image below illustrates what I just said:
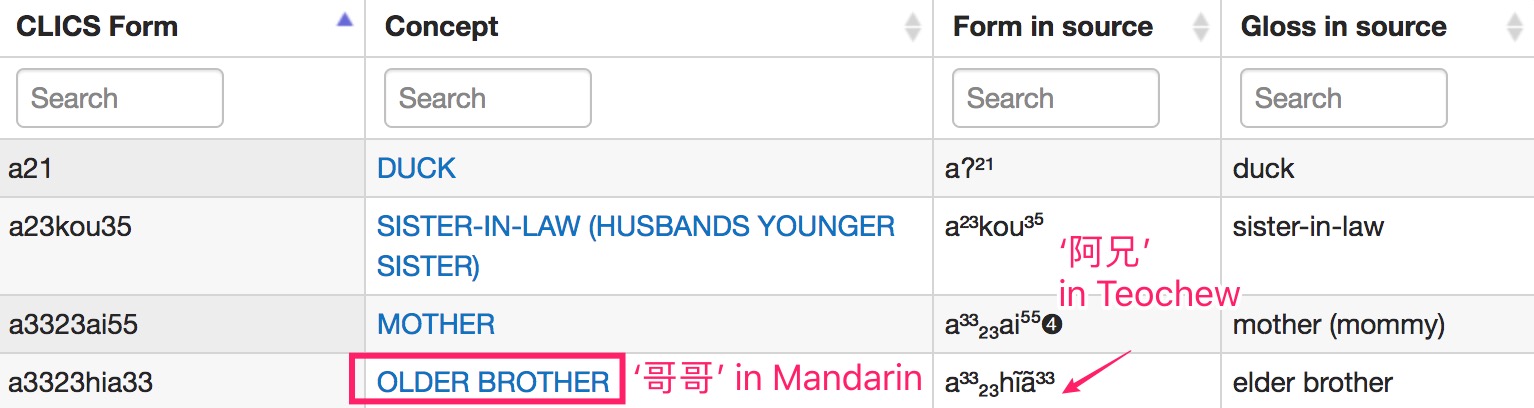
Luckily, the page contains the link to the source dataset from 1964. This originial dataset has complete information regarding how a word is pronounced. It breaks down characters of a word into phonemes in each language, which is handy as we will be doing analysis on initials, finals, and tones. Also each word across different dialects is linked by a unique identifier.
Data Wrangling
I used Python and Pandas for data wrangling. The full code is in my github repo, if you are interested in the detail. In retrospect, I would like to make notes on places that I found interesting.
Inner Join
From the original dataset, I extracted Beijing and Teochew words into two Pandas DataFrames. A snippet of the merged dataset looks like the following:
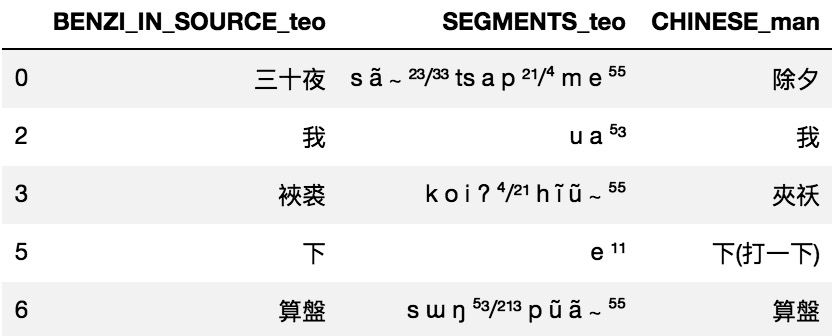
I chose inner join that merges two DataFrames based on the unique identifier.
The column named BENZI_IN_SOURCE_teo is where the Chinese characters corresponding to Teochew pronounciation are. When I converted that column to Pinyin (the romanization of the Chinese characters), I obtained a one-to-one correspondence at the character level.
Explode
This Pandas function Explode is exactly as it suggests, that is, to “explode” list-like elements of the DataFrame into many rows. For example, I first converted the column “三十夜” into [’三‘, ‘十’, ‘夜’], then do the explode operation to put these three characters into three different rows.
The last thing is to combine all the “exploded” DataFrames into one. Now we have successfully converted the DataFrame into a long format.
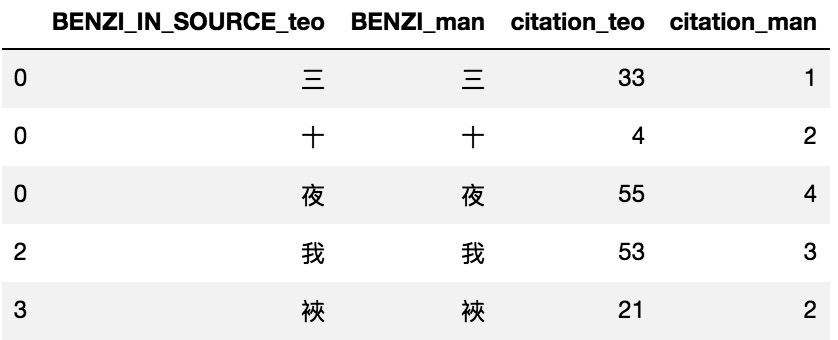
I like this function because it utilizes the vectorization aspect of Pandas, as opposed to looping through each row of the DataFrame and writting characters into multiple rows.
Citation Tones or Sandhi Tones?
The Teochew dialect has a complex tonal system in part because characters often change from their citation tones to sandhi tones. Sandhi occurs when one character precedes another character and the former changes to its tonal variation.
In part 1 of this series, I will only explore the citation tones. However, pronounication prediction will inevitably involve sandhi tones as words rather than single characters appear the most.
The nice thing about this dataset is that citation and sandhi tones are labelled separately.
Careful, Careful, Careful
Bugs in a data science project is harder to spot compared to those in software development. When you think there is no bug, double check the data. It is likely that you mishandled the data, did not notice, and have a “garbage” result that makes no sense.
Data Visualization
Contingency Table
After the data wrangling, here comes the more exciting part: data visualization. There are eight tones in Teochew and five tones in Mandarin. To see if there is any regular correspondence in tones, I plotted them as a contingency table.
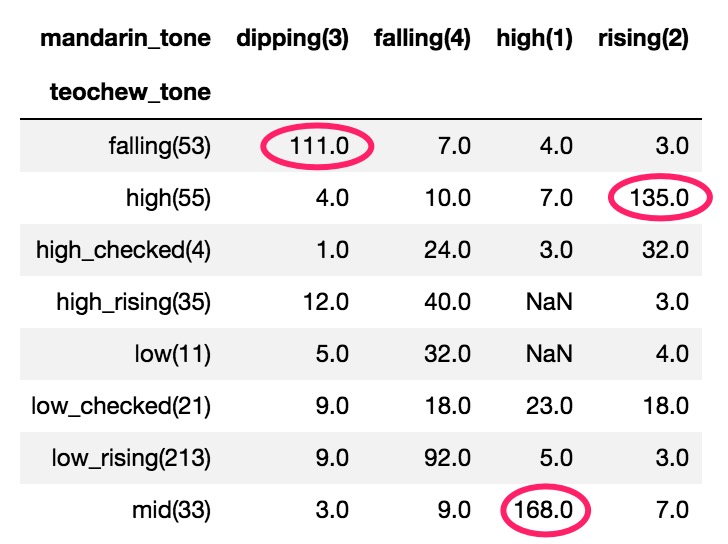
There are in total 801 distinct characters and we can see some correspondence here: For example, the mid tone in Teochew corresponds to the high tone in Mandarin; the high tone in Teochew and rising tone in Mandarin often occur together, etc.
Correspondence Analysis
Another way to view the contingency table is by using correspondence analysis. Here is a great video that explains how it works.
Basically, corrrespondence analysis is similar to PCA, but for categorical values. The distances on the plot show how rows/columns are grouped together.
I used ggplot2 and ggrepel in R to do the job. The graph is shown below:
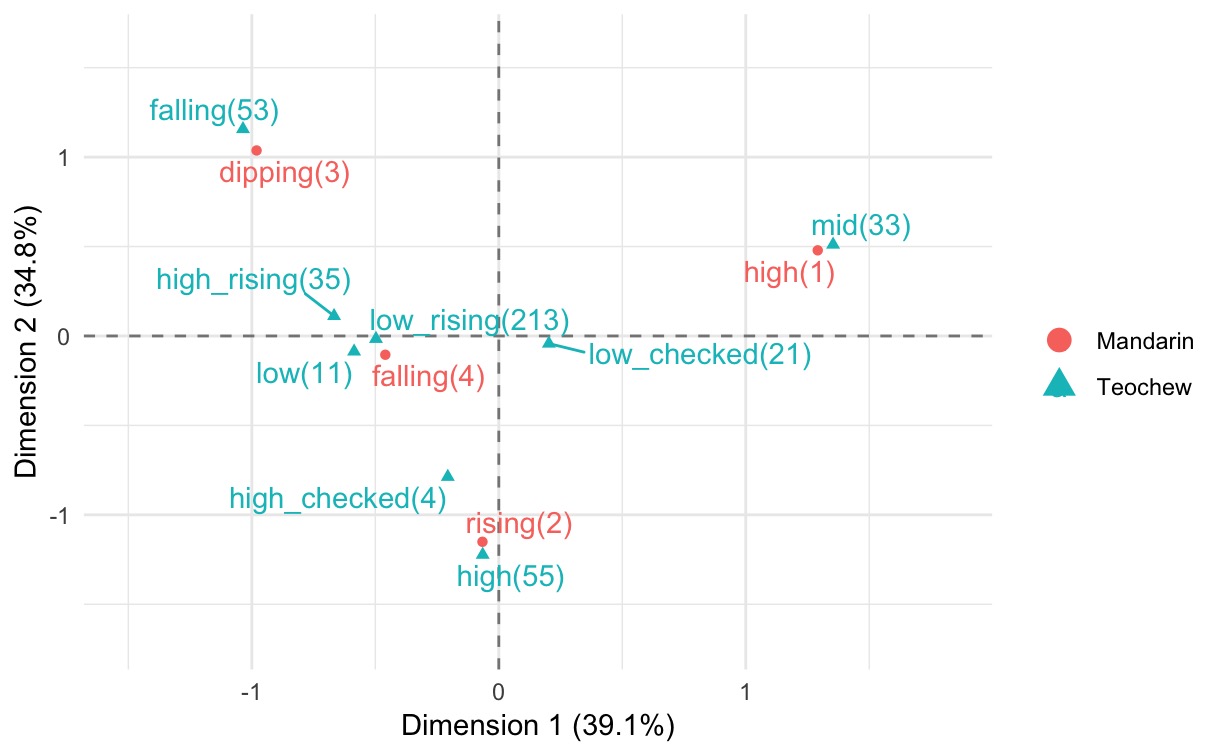
The two dimensions capture 73.9% of the variation in the data. Columns and rows that are close to each other in the plot have simlar frequency counts. This result matches with what we saw from the contingency table, where the mid tone in Teochew is related to the high tone in Mandarin, falling tone in Teochew to dipping tone in Mandarin, and rising tone in Teochew to high tone in Mandarin.
Another finding is that the low rising and low tones in Teochew, and the falling tone in Mandarin, form a cluster in the middle. There are probably lots of low rising and low tones in Teochew associated with the falling tone in Mandarin.
Those are just my speculations. In my subsequent posts, I will compare these with character pronounciation predicted by the model.
More to come
Thanks for making this far:p I will talk more about this project in the coming weeks. Meanwhile you can stay tuned and check out my other posts!