
BERT, you are more [MASK] than a pig
In this blog post, I want to talk about BERT and its architecture from a practical perspective. To make this fun to read, I am gonna show some examples of multilingual BERT.

BERT, which stands for Bidirectional Encoder Representations from Transformers, is a language representation model released by Google in Devlin et al. (2019).
There are many natural language processing tasks that BERT achieves state-of-the-art results. While tasks such as question answering and named entity recognition are very interesting, I favour “fill in the blanks” type of problem, or a cloze test.
As you may notice, the title of this blog post is an example of a cloze test: BERT, you are more [MASK] than a pig.
In this task, BERT needs to predict the masked word based on its surrounding context. Let’s dive into the model’s architecture!
Transformer
The Transformer encoder (Vaswani et al., 2017) is the building block of BERT. Therefore, this section is dedicated to explain the Transformer at a higher level.
Note: The original Transformer consists of an encoder and a decoder; Unless otherwise stated, the Transformer in this blog post refers to the whole architecture with encoder and decoder, and not just the encoder in BERT.
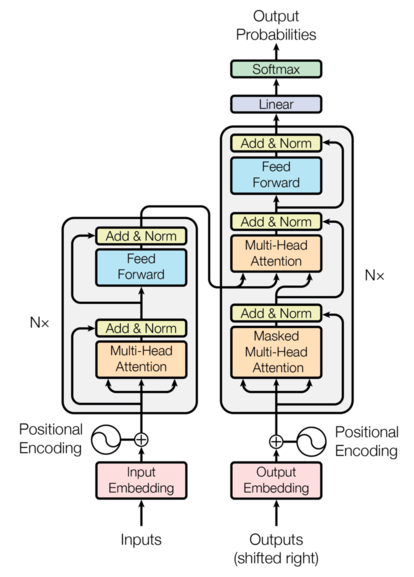
The Transformer consists of 6 identical layers for encoder and decoder, respectively. Each layer has a multi-head attention and a fully connected feed-forward network (The graph above represents one Transformer block/layer).
The Transformer is trained to perform machine translation, for example, the inputs are tokens from English sentence “I like ice cream” and the outputs in Chinese would be, “我喜欢冰淇凌’’.
One training sample can have all the inputs “I like ice cream”, together with the previous outputs “我喜欢”, and the Transformer predicts the output (which is “冰”) one at at a time.
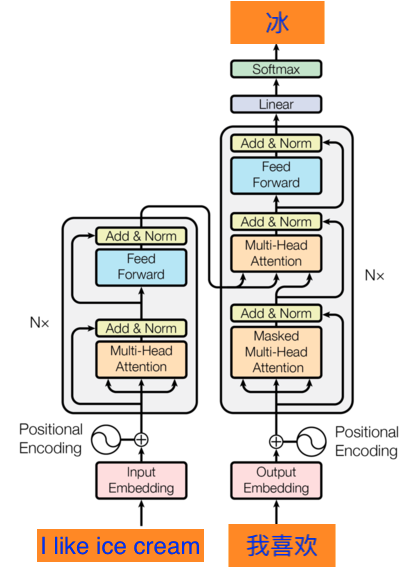
Input embedding for each token is a vector space in which words with similar meaning stay close to each other, and vise versa.
In addition, the Transformer adds positional encoding to the input embedding. As its name indicates, positional encoding is a representation of the order of words, so that order is preserved.
Multi-Head Attention
There are THREE multi-head attention blocks in the Transformer.
The self-attention block in the encoder attends to all inputs while the masked one in the decoder attends to only the preceding outputs.
There is a special multi-head attention in the decoder, we call it encoder-decoder attention. The interaction between the inputs and the outputs actually happens there.
That attention takes keys and values (both are vectors) from the encoder, and uses the outputs from the decoder attention as queries (vectors too).
The original paper has multiple attention heads to improve performance, as opposed to a single scaled dot-product attention.

Having covered the most important part of the Transformer, I will not talk about the feed-forward networks and layer normalization, but I encourage you to watch this YouTube video for more detail.
BERT
As mentioned, the architecture of BERT is basically built out of Transformer blocks.
But the ability of BERT lies beyond that.
Pre-training BERT
In BERT’s pre-training, Masked Language Model (MLM) and Next Sentence Prediction (NSP) are two unsupervised tasks to construct the language model using large amount of unlabelled data.
Masked LM
The idea is not new, but it is the first time being applied to a language model.
BERT has some inputs masked out and only predicts the outputs for those masked tokens. Masking out some words “forces” BERT to learn the contexts of the sentence.
Next Sentence Prediction (NSP)
Aside from token-level task, BERT introduces NSP to explore sentence-level relationships.
In the pre-training phase, sentence A are treated as the inputs, and given sentence B, BERT needs to find out whether sentence B follows sentence A in the actual corpus.
Hypothetically, NSP can contribute to question answering and natural language inference. However, subsequent analysis (Liu et al., 2019) argues that NSP is not very helpful in itself.
Fine-tuning BERT
After pre-training BERT, we need to fine-tune it for different downstream tasks using domain-specific labelled data.
To quickly experiment with BERT, I do not fine-tune the model myself and instead use bert-large-uncased and bert-base-chinesefrom Hugging Face.
Pop quiz! BERT
Let’s start with bert-large-uncased model, and see how it performs on some examples from CPRAG-34, a dataset to test how human brain reacts to different types of cloze tests.
The dataset is made up with 34 pairs of sentences, each one with several choices for completing the blank. Only one of them is expected and the others are considered inappropriate.
For example, consider the following text:

From the word “Checkmate”, we know the answer for the [MASK] should be chess.
And when we present three choices to BERT, it picks the correct one with the highest score. Good job!

What about girl’s makeup ![]()
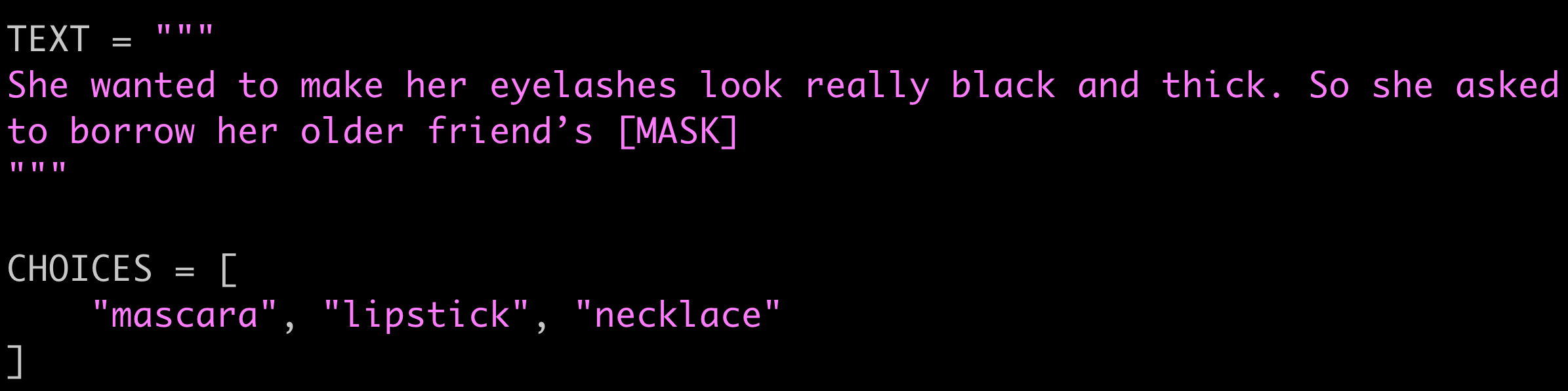
Here is the answer from BERT:

Once again, mascara is the highest.
One more example:
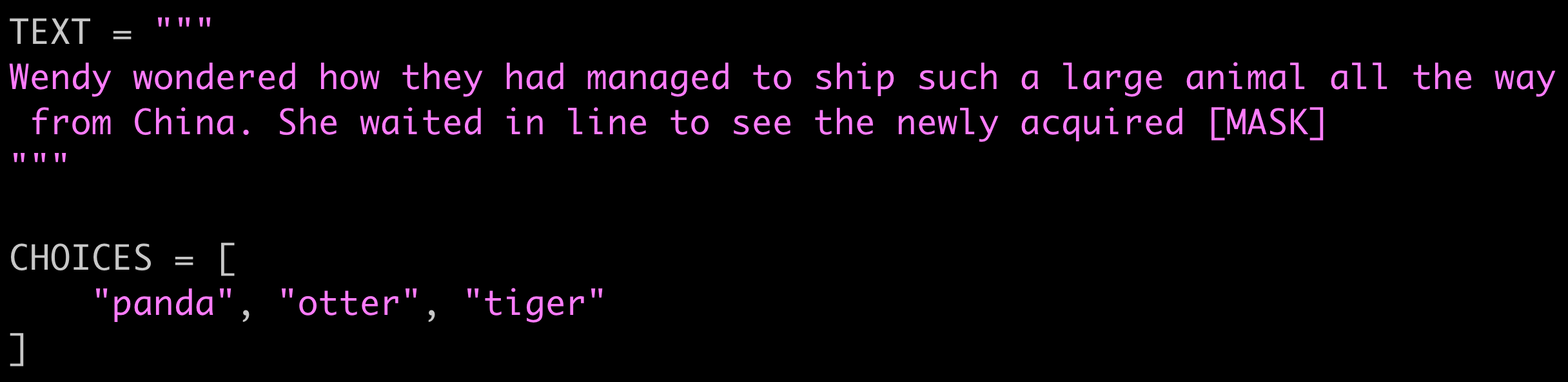
And here is BERT’s answer,

Who doesn’t like pandas?
Chinese BERT
Unlike English, Chinese does not have spaces between characters, and the majority of words are made of two characters.
If we try to predict two masks independently, BERT would not be guaranteed to produce words that make sense together.
So instead of masking out just one character, I modify the code to predict the first token, select the top 3 characters with the highest probability, and use those to predict the mask for the second token, and so on.
Here I choose the two-line poem titled “A Generation”, composed by the famous contemporary Chinese poet Gu Cheng.

Literal translation: The dark night gave me black eyes, But I use them to seek ???
And here are the top nine results from BERT:

Those look reasonable, and I want to end this blog post by the original sentence:

Literal translation: The dark night gave me black eyes, But I use them to seek the light.
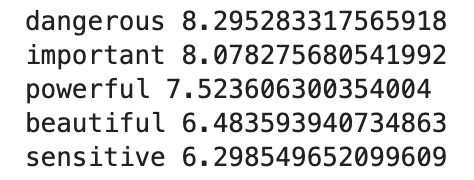
Lastly, in case you are wondering about the title: “BERT, you are more [MASK] than a pig”
Here are BERT’s answers ![]()
References
Devlin, Jacob, et al. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” ArXiv.org, 24 May 2019, arxiv.org/abs/1810.04805.
Vaswani, Ashish, et al. “Attention Is All You Need.” ArXiv.Org, 2017, arxiv.org/abs/1706.03762.
Liu, Yinhan, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019.