
What I learnt from DDIA
Designing Data-Intensive Applications (DDIA) is the first book I read about distributed systems, covering a variety of topics such as replication and partitioning for databases. It is language agonistic, and has abundant industrial examples (such as Twitter) to explain design choices in practice.
I like the way Martin Kleppmann conveys difficult concepts, however, it is by no means an easy read. For me, 20 pages a day is the right amount to keep engaged without feeling like it’s too much.
DDIA is good for the beginner who wants to learn about distributed systems, or people with a few years of experience who would like to deepen their knowledge.
In this blog post, I am happy to share some interesting takeaways. I hope that more people would read this book!
1. Clocks
In a distributed system, it is hard to make different partitions agree on time. Usually every computer has its own clock, physically embedded in the hardware. Understandably there is some degree of difference between clocks. The common practice is to adopt Network Time Protocol (NTP) for different clocks to synchronize.
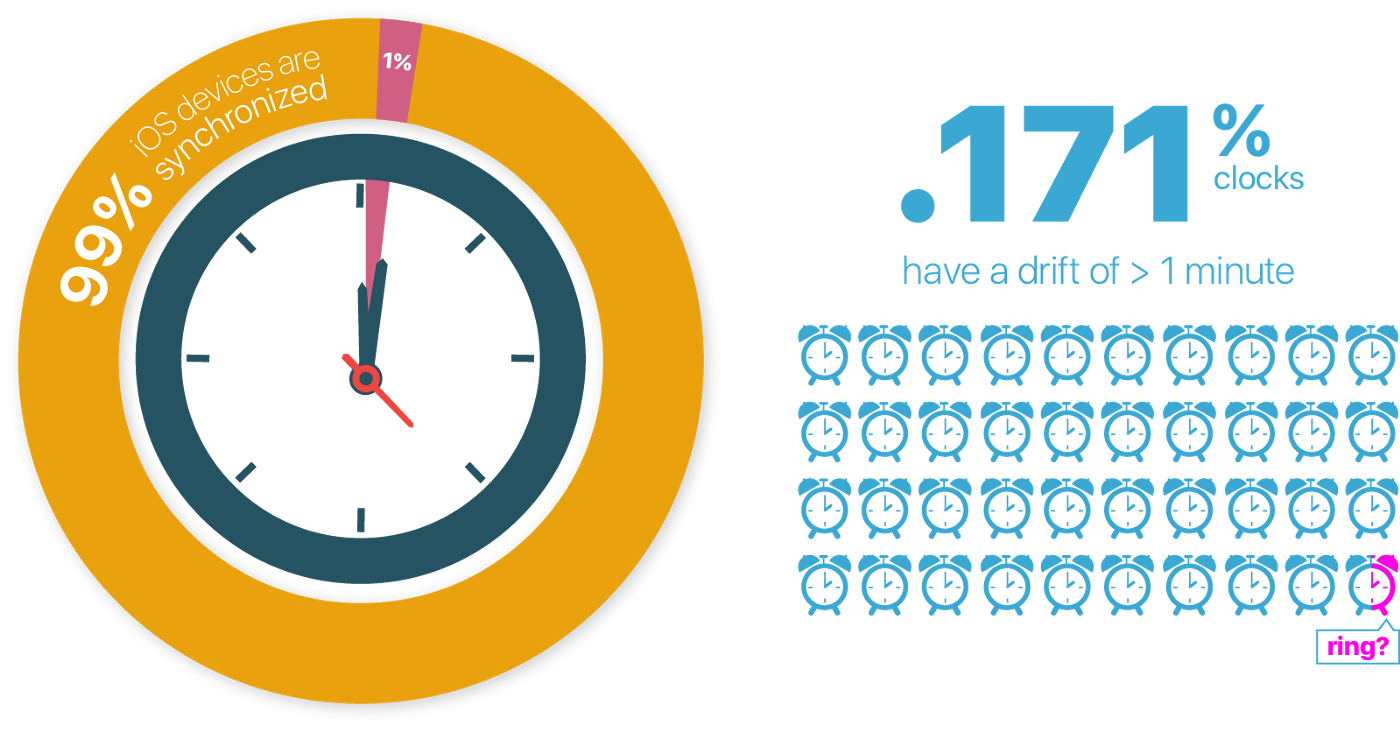
However, there are cons to this approach. For example, due to network delay, local clocks and NTP may have some time lapses and synchronization becomes difficult. Another example is when we do not have control over users’ devices, whose clocks are somehow untrustworthy.
It is difficult to trust one node’s notion of time, let alone multiple other things. Can we solve the problem via majority voting (quorum)? The answer is consensus.
2. Consensus

In a single leader database, one node processes all the writes, and replicates them to all its followers. When outages happen on the leader’s node, or GC pause takes unexpectedly longer, other nodes will need to achieve consensus on when to take over.
There are many consensus algorithms with similar high-level ideas. One is to use epoch number, which increases monotonically. When the majority of nodes think the old leader is dead (could still be alive!), they will vote for a new leader. This new round of election is associated with a new epoch number. Therefore, any leader needs to check whether someone else has a higher epoch number before making decisions.
You cannot declare leadership without others’ consensus! (does not apply for Canadian election)

3. Publish/Subscribe
Compared to request/response interaction, the author thinks publish/subscribe dataflow is the future. Instead of querying a current state from the database, pub/sub is about subscribing to a change.
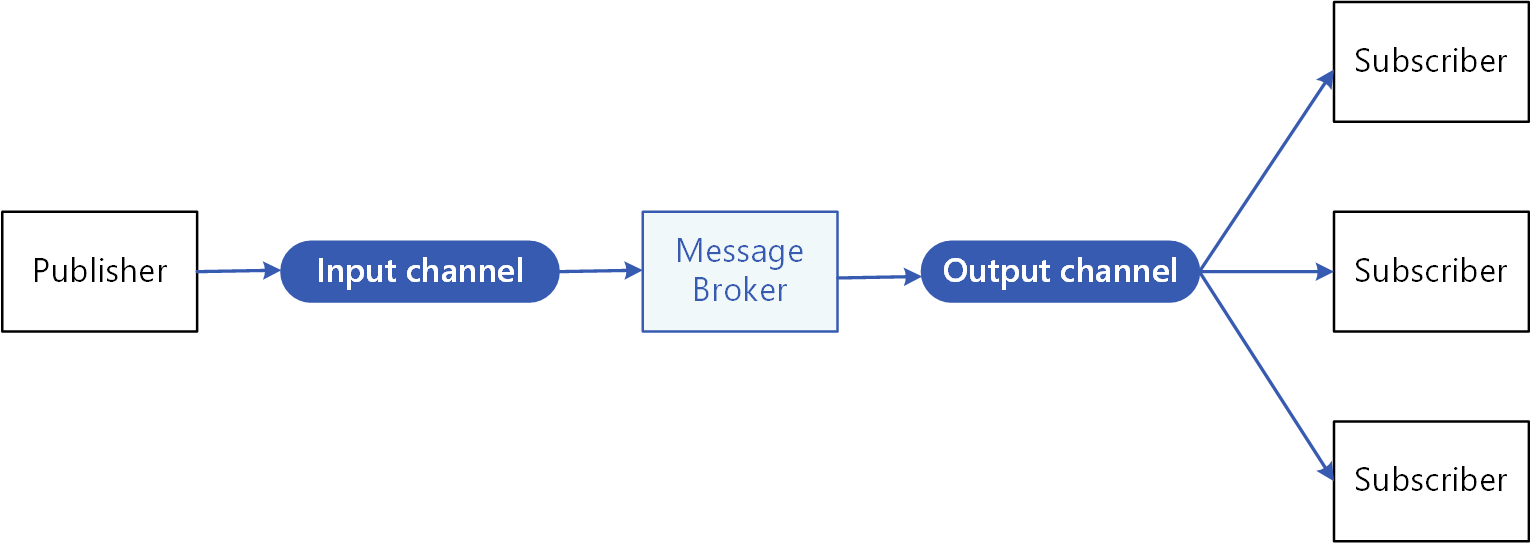
He argues, first, it is hard to determine the serialized order in which two concurrent requests are received by the server. It is error-prone when they compete to modify the same object state. Especially for multiple servers. They cannot agree on the notion of time! On the other hand, pub/sub model only allows for a single source of truth, and we can have as many derived data views as we want.
Second, idempotency would be an issue. Due to network delay, a client may send the same request twice. For the request/response model, the side effect of processing the same request can be disastrous unless the system is carefully designed. We can avoid the same problem for pub/sub. For example, if each event is appended to a log file, then getting the state is simply to “replay” all the events (over some period).
Some people say this book is worth reading more than once; while it may be true, there is nothing wrong with skipping some pages when it gets too difficult.

Hope you enjoy the read and see you next time!